| Главная » Статьи » Excel » Макросы и программы VBA |
Проблема нечёткого поискаКогда мы имеем дело с текстом, вводимым человеком, то в нём неизбежны ненамеренные ошибки. Вместо "пер. Гоголя" человек может набрать "пер. Ноголя" просто потому, что промахнётся по нужной клавише и нажмёт соседнюю. В виду этого, возникает задача поставить в соответствие введеному слову слово словарное, которое в наибольшей степени похоже на то, что ввёл пользователь. Классическая задача - верификация названий улиц, населенных пунктов и т.п. Обычный поиск тут бессилен, так как введенное слово в словаре отсутствует. Обычный поиск в состоянии только установить этот факт, но не в состоянии предложить пользователю на выбор наиболее близкие варианты. Нужна реализация нечёткого поиска. Что я предлагаю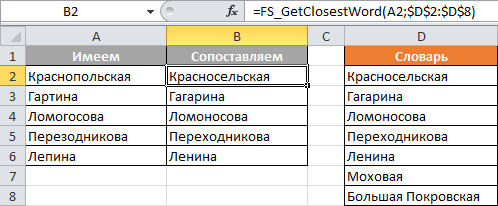
Для тех, кто спешит, сразу сообщаю, что, если тема актуальна, то я предлагаю вам воспользоваться своей пользовательской функцией рабочего листа, которая называется FS_GetClosestWord и имеет 2 обязательных параметра и 4 необязательных. Формат вызова: =FS_GetClosestWord( What ; Where ; [NumItem] ; [MinLen] ; [Compare] ; [Dbg] ) , где:
Большинство пользователей обойдутся первыми двумя параметрами. Скачать файл с функциейСкачатьЕсли будете переносить руками в свой Excel VBA проект, то не забудьте помимо модуля Fuzzy, также перенести класс Search. 
Теория нечёткого поискаИзучая вопрос, в начале заглянул к Николаю Павлову в этот его рецепт. Даже нашёл у него ошибки. Однако с самого начало было понятно, что предложенный алгоритм для общего случая будет неприемлем из-за медленной скорости, поэтому изыскания были продолжены. Отличный обзор алгоритмов нечёткого поиска дан в этой статье. Для своей реализации я выбрал метод N-грамм с привлечением хэширования по сигнатуре для оценки найденных вариантов. Предположим, что у нас в словаре есть слово ПОМИДОР. Мой алгоритм разбивает это слово на подстроки длиной от 7 до 3 символов. 7 - длина слова в данном случае, а комбинации символов короче трёх символов использовать особого смысла нет.
Все эти 15 комбинаций я помещаю в словарь. В этот же словарь заносятся все новые комбинации, образующиеся от остальных словарных слов. Далее берётся искомое слово и точно также разбивается на подстроки и прогоняется на совпадение с созданным словарём буквенных комбинаций. Все срабатывания заносятся в коллекцию и ранжируются по уровню похожести. Проблемы реализации нечёткого поискаНа мой взгляд основная проблема тут - скорость поиска. Надо заметить, что прежде, чем я получил тот код, который вам предлагаю, я написал промежуточную статью про эффективность структур данных и перепробовал массу промежуточных вариантов структур и алгоритмов. Поскольку всё реализовано в виде формулы рабочего листа, то основной способ улучшить производительность - это, чтобы каждая формула не расчитывала свою коллекцию буквенных комбинаций словаря, а использовала результаты однажды проделанной работы. Это было сделано через глобальные структуры. Однако это всё означает, что формула не отслеживает изменения в массиве Where. То есть считается, что диапазон Where статический и меняется редко. Надеюсь вы найдёте этот функционал полезным. Если вам данное решение по какой-то причине не подошло или нуждается в серьёзной модификации, то дайте знать, возможно, я его доработаю, так как тема довольно интересная. Читайте также: | |
| Просмотров: 20765 | Комментарии: 8 | | |
| Всего комментариев: 8 | |||||||
| |||||||
