| Главная » Статьи » Excel » Макросы и программы VBA |
Содержание:1. Что такое Dictionary?2. Создание Dictionary3. Свойства и методы объекта Dictionary4. Наполнение словаря4.1. Типы данных ключа и элемента4.2. Через метод Add4.3. Через свойство Item4.4. Неявное добавление ключа в Dictionary5. Удаление элементов5.1. Удаление конкретного элемента5.2. Очистка всего словаря6. Ключи6.1. Последовательность хранения6.2. Добавление элементов с ключами разных типов6.3. Уникальность строковых ключей6.4. Генерация уникальных ключей7. Элементы7.1. Типы элементов7.2. UDT8. Доступ к элементам словаря8.1. Извлечение элемента по ключу8.2. Извлечение элемента по номеру его индекса8.3. Извлечение ключа по номеру его индекса9. Перебор словаря9.1. For each по массивам Keys и Items9.2. For по массивам Keys и Items9.3. Фильтрация элементов9.4. Выгрузка словаря в диапазон ячеек9.5. Операции с ключами/элементами при помощи формул рабочего листа10. Файл примера11. Заключение12. Использованный источник1. Что такое Dictionary?Если вы программируете на VBA/VBS, то рано или поздно вынуждены будете познакомиться с объектом Dictionary. Если в двух словах, то Dictionary - это продвинутый массив. Как вы знаете, массив - это упорядоченный набор неких (обычно однородных) элементов. Вот типичный массив: 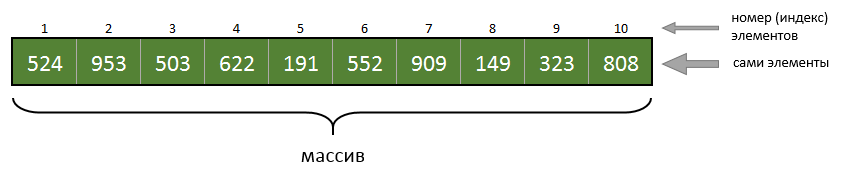
Элементы пронумерованы и доступны по номеру индекса. Индекс всегда числовой. А вот, что из себя представляет Dictionary (словарь): 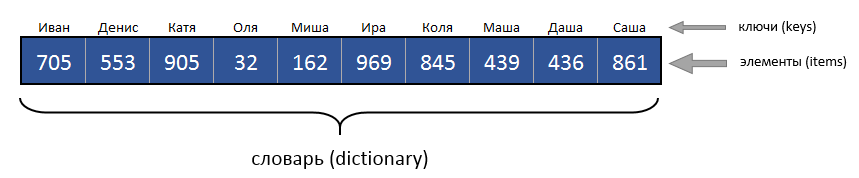
Как видите, каждому элементу поставлен в соответствие не просто числовой индекс, а уникальный ключ, который в данном случае представляет из себя текстовую строку (имена). Двух одинаковых ключей в словаре быть не может, но могут быть одинаковые элементы (хоть все одинаковые). Таким образом словарь - это обычно некий список, снабжённый ключом, при помощи которого вы хотите извлекать полезную информацию (элементы). В указанном примере мы имеем, допустим, имена детей в качестве ключа, а в качестве элементов, поставленных в соответствие ключу, скажем, количество карманных денег у ребёнка. С другой стороны нечто подобное можно же сделать, используя массив. Давайте объявим двумерный массив: Должно быть у словаря есть какие-то преимущества перед таким использованием массивов? И это действительно так! Давайте пока просто перечислим важнейшие преимущества:
2. Создание DictionaryСуществует несколько способов создать объект типа Dictionary. Ознакомимся с ними: Считается, что методы, использующие позднее связывание надёжнее в плане обеспечения работоспособности программы на разных компьютерах, так как не зависят от настроек Tools - References... редактора VBA. 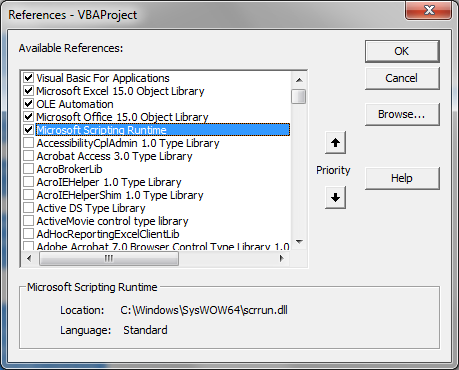
Однако, учитывая, что библиотека Microsoft Scripting Runtime присутствует везде, начиная с Windows 2000, я думаю, что вы без какого-либо ущерба можете использовать методы раннего связывания. Раннее связывание хорошо тем, что оно несколько быстрее работает, а также во время разработки вы можете пользоваться функцией завершения кода (когда среда программирования вам подсказывает имеющиеся у объекта свойства и методы). Выбор за вами. 3. Свойства и методы объекта Dictionary
4. Наполнение словаря4.1. Типы данных ключа и элементаDictionary наполняется по одному элементу. Не существует способов наполнить словарь массово. Чтобы добавить в словарь новый элемент вы должны иметь уникальный ключ и сам элемент, который под этим ключом будет храниться в словаре. В качестве типа данных для элемента может быть использовано практически всё что угодно: числа, логический тип, строки (в том числе пустые), дата-время, массивы, любые объекты (листы, диапазоны, коллекции, другие словари, пустой указатель Nothing). В качестве типа данных для ключа могут быть использованы: числа, строки, дата-время, объекты, но не массивы. UDT (User Defined Type) не может напрямую использоваться в качестве ключа и/или элемента, но данное ограничение можно обойти, объявив аналог UDT, создав класс и определив в нём свойства аналогичные имеющимся в UDT. А поскольку класс - это объектный тип, то его уже можно использовать для ключей и элементов. 4.2. Через метод AddНа листе Example, прилагаемого к статье файла, есть таблица с TOP30 стран по площади их территории. Для области данных этой таблицы объявлен именованный диапазон SquareByCountry. Пример ниже добавляет все строки указанногот ИД в Dictionary по принципу страна (key) - площадь (item): Как видите, для добавления элемента (item) мы в 12-й строке кода использовали метод Add объекта dicCountry. Если в нашей таблице будет задвоена страна, то при попытке добавить в словарь элемента с ключом, который в словаре уже есть, будет сгенерировано исключение: 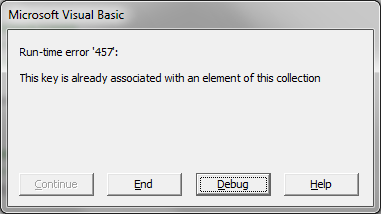
4.3. Через свойство ItemИспользуя свойство Item, также можно добавлять пары ключ-элемент, однако, при попытке добавить дублирующий ключ исключения сгенерировано НЕ БУДЕТ, а элемент будет заменён на новый (с потерей старого). Это очень полезно - иметь возможность выбирать способы наполнения словаря, отличающиеся реакцией на задвоение ключей. 4.4. Неявное добавление ключа в DictionaryИ ещё один неожиданный и я бы сказал экзотический способ пополнения словаря. Если упомянуть свойство Item по ПРАВУЮ сторону оператора присваивания, то он оказывается добавит в словарь key с пустым item, если данного key не существует в коллекции. Если же такой key уже существует, то никаких действий предпринято не будет. Ещё раз хочу обратить ваше внимание, что элемент (item) при таком пополнении коллекции будет пустым (Empty). Это можно использовать, если вам нет необходимости что-то хранить в элементах в качестве полезной нагрузки (например, когда вы просто строите список уникальных значений, встречающихся в столбце таблицы). Если вы читаете словарь через Item (а это, собственно, самый логичный и распространенный метод), и при этом хотите избежать добавления пустых ключей в словарь, используйте предварительно метод Exists, что контроля наличия такого ключа в коллекции. 5. Удаление элементовЕсть 2 варианта удаления элементов из словаря: 5.1. Удаление конкретного элемента5.2. Очистка всего словаряПолагаю, комментировать тут нечего. 6. Ключи6.1. Последовательность храненияСледует понимать, что элементы в словаре хранятся в той последовательности, в которой они добавлялись в словарь. Менять эту последовательность можно только путём полной перестройки словаря (хотя не совсем понятно для чего это может понадобиться). 6.2. Добавление элементов с ключами разных типовПродемонстрируем, добавление элементов с ключами разных типов в словарь: Вот, что мы получим, выполнив представленный код: 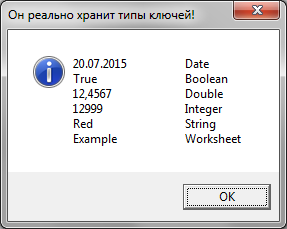
6.3. Уникальность строковых ключейПри помощи свойства CompareMode можно управлять тем, как Dictionary будет реагировать на одинаковые текстовые ключи, набранные в разном регистре. При значении CompareMode равным константе TextCompare (1) разный регистр игнорируется и ключи считаются идентичными, а при константе BinaryCompare (0) такие ключи считаются разными. Менять CompareMode можно только, когда словарь пуст (либо только создан, либо только что очищен). 6.4. Генерация уникальных ключейИногда требуется сохранить в Dictionary все элементы, а какие при этом будут ключи нам всё равно - лишь бы они были уникальные, так как в противном случае мы можем потерять некоторые элементы (items). В таких случаях очень удобно использовать свойство Count в качестве генератора уникального значения ключа, так как Count гарантированно увеличивается на единицу всякий раз, когда добавляется элемент. 7. Элементы7.1. Типы элементовПродемонстрируем добавление в словарь элементов разных типов: 7.2. UDTКак я уже упоминал, напрямую переменные типа UDT нельзя сохранять в качестве элементов Dictionary. Чтобы это обойти нужно вместо UDT создать модуль класса, полностью соответствующий структуре необходимого вам UDT. Например, я создал модуль класса с названием MyRGB и определил его так: далее становится возможным следующее: 8. Доступ к элементам словаря8.1. Извлечение элемента по ключуЭтот способ мы уже обсуждали, но для полноты картины повторимся. Мы используем свойство Item с указанием ключа. Если ключа не существует, то будет возвращено значение Empty, а в словарь добавлен данный ключ со значением Empty в качестве элемента. Никаких исключений не генерируется. Если хотите избежать добавления ключа в коллекцию, используйте предварительно метод Exists для проверки его наличия. 8.2. Извлечение элемента по номеру его индексаДля извлечения конкретного элемента по его индексу необходимо использовать конструкцию Items()(i), где i - индекс элемента, начинающийся с нуля. Это довольно неожиданный синтаксис, я не припомню, чтобы он применялся где-то ещё кроме Dictionary. Согласно таблице, приведенной выше, Items - свойство, содержащее одномерный массив всех элементов словаря. Также есть соответствующий массив Keys для всех ключей словаря. 8.3. Извлечение ключа по номеру его индексаБезусловно то же самое справедливо и для извлечения ключей. 9. Перебор словаря9.1. For each по массивам Keys и Items9.2. For по массивам Keys и Items9.3. Фильтрация элементовДля фильтрации словаря по ключам или элементам крайне удобно использовать VBA функцию Filter. Вот как это может выглядеть: 9.4. Выгрузка словаря в диапазон ячеекРезультат: 
9.5. Операции с ключами/элементами при помощи формул рабочего листаЕсли ключи/элементы у вас в виде числовых значений, то к ним легко можно применять стандартные функции рабочего листа. Например, ниже я определяю страну с наибольшей территорией и вывожу её название. Числовую территорию в данном случае желательно иметь в виде ключа, так как зная ключ, вывести элемент легко, а вот, зная элемент, найти по нему ключ, гораздо сложнее (потребуется перебор всего словаря). К вашим услугам и другие функции, такие как: Min(), Large(), Small() и т.д. 10. Файл примераСкачать примеры кода VBA11. ЗаключениеЯ надеюсь, что данная статья помогла вам хорошенько разобрать с объектом Dictionary. В моих ближайших планах рассказать, как при помощи словаря строить произвольные иерархические структуры. Так же стоит упомянуть, что в VBA есть такой встроенный объект Collection. Однако, по своим функциональным возможностям он достаточно уныл и вчистую проигрывает Dictionary, поэтому я не хочу тратить на него силы и время. Единственное его преимущество это то, что он часть MS Office, а словарь - часть MS Windows, поэтому первый работает в MS Excel for Mac, а второй - нет. Но пока (да и вообще) в нашей стране это обстоятельство можно с лёгкостью игнорировать. 12. Использованный источникМассу конкретного материала по объекту Dictionary я подчерпнул из этой замечательной (огромной!) статьи некоего, по всей видимости испанского, автора, имени которого на сайте нет. Очень рекомендую. На сайте также даётся огромное количество примеров работы с объектной моделью Outlook! Читайте также: | ||||||||||||||||||||||||||||||||||
| Просмотров: 117271 | Комментарии: 65 | | ||||||||||||||||||||||||||||||||||
| Всего комментариев: 65 | 1 2 » | ||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
| 1-10 11-15 | |||||||||||||||||||||||||||||||



