Аудитория данного цикла статей
Данный цикл статей будет адресован в помощь аналитикам, финансовым в первую очередь, так как на примере стандартной финансовой информации я буду разбирать наиболее рациональные и удачные, с моей точки зрения, Excel-приёмы по её обработке. Во главу угла будет поставлено сокращение трудозатрат по подготовке финансовых отчётов, а также повышение их качества и технологического совершенства. Для усвоения материала необходим продвинутый уровень владения Excel или около того.
Борьба за единственный источник данных
Одним из ключевых факторов, который ведет к тому, что подготовка отчётности занимает значительное время - это то, что в процессе подготовки данных используется несколько таблиц. Очень часто количество и структура данных становятся заложниками визуального компонента отчетности. В худшем случае под каждый вид отчёта используется свой, уникальный источник данных, а то и несколько. А когда у вас несколько источников данных, то вы начинаете их сверять между собой, чтобы убедиться, что они не потеряли целостность. Замкнутый круг. Поэтому для хорошего аналитика очень актуальна задача - держать под контролем количество источников данных. В идеале иметь ОДИН. В этой статье будет использоваться один источник данных - лист DATA и будет продемонстрирован довольно продвинутый и удобный способ извлечения данных из него.
Модельные данные
На примере довольно сложного отчёта западного бухгалтерского учёта P&L (Profit and Loses, отчёт о прибылях и убытках) я попытаюсь проиллюстрировать все идеи данного цикла. Я подготовил большой массив данных, необходимых для создания P&L отчёта, которые, как я надеюсь, вполне адекватно отражают реальный уровень сложности информации такого рода.
Таблица параметров, используемых в моделе:
|
Параметр в модели
|
Англоязычный термин, единицы измерения
|
Русскоязычный аналог, формулы
|
|
VOL
|
VOLUME, units
|
Объем продаж. Единицы измерения, физические единицы продукции: ящики, упаковки, штуки.
|
|
GRREV
|
GROSS REVENUE, РУБ
|
Суммарный доход от продаж без учета скидок
|
|
DEDUC
|
DEDUCTIONS, РУБ
|
Различного рода скидки: скидки, отраженные в счетах, скидки по контракту, за выполнение обязательств клиентом, и прочее
|
|
NREV
|
NET REVENUE, РУБ
|
Чистый доход. Вычисляется, как NREV = GRREV - DEDUC
|
|
PRD
|
PRODUCTION COST, РУБ
|
Затраты на производство (приобретение) реализуемой продукции: сырье, затраты на производство, затраты на транспортировку внутри компании
|
|
GRPRF
|
GROSS PROFIT, РУБ
|
Валовая прибыль, вычисляется как: GRPRF = NREV - PRD
|
|
OPEX
|
OPERATING EXPENSES, РУБ
|
Операционные затраты, не включаемые в прямую себестоимость продукции
|
|
EBIT
|
EARNINGS BEFORE INTEREST AND TAXES, РУБ
|
Операционная прибыль, вычисляется как: EBIT = GRPRF - OPEX
|
|
DA
|
AMMORTIZATION, РУБ
|
Аммортизация, переоценка активов
|
|
EBITDA
|
EARNINGS BEFORE INTEREST, TAXES, DEPRECIATION AND AMORTIZATION, РУБ
|
Операционная прибыль плюс аммортизационные отчисления, EBITDA = EBIT + DA
|
Скачать пример
Файл H2A-p1.xlsx
Структура таблицы, которая будет служить для вас источником данных исключительно важна. Основное правило, которое надо запомнить: не плодите лишних столбцов. Отметим, что мы НЕ стали делать отдельные колонки для параметров VOL, GRREV, DEDUC и т.д., а ввели их всех вместе в колонку TYPE! Тем самым мы существенно упростили нашу таблицу и дальнейшую выборку из неё. Кстати, это же самое правило облегчает анализ данных в сводных таблицах. Тема эта, однако, сильно выходит за рамки данной статьи, тем же, кому интересно, следует гуглить "реляционная модель + нормализация данных".
Измерения модели данных
|
Колонка таблицы DATA
|
Комментарии
|
|
TYPE
|
В этой колонке хранятся идентификаторы данных, описанный в таблице выше. То есть, если значение ячейки VOL, то значит это объём продаж. Какой именно это объём продаж зависит от всех измерений в других колонках.
|
|
SUBTYPE
|
Более мелкая классификация параметров из предыдущей колонки. Например, GRREV в колонке SUBTYPE имеет только значение ALL, то есть не имеет подтипа, а, к примеру, тип DEDUC имеет целых 5 подтипов от D1 до D5, что говорит о наличии пяти типов различного рода скидок. Вас не должны смущать, что используется константа "D1" вместо "Скидки в счёте", там и тогда, когда это будет необходимо D1 будет заменено на нужную строку.
|
|
SEG
|
Сегменты продаж с точки зрения типа клиента, от S1 до S2. Например, S1 = Розница, S2 = Ключевые клиенты.
|
|
BUS
|
Классификация продаж с точки зрения реализуемого продукта. От B1 до B3. Например, в моей любимой Кока-Коле это традиционные бренды, соки и алкоголь. Будем называть это типом бизнеса.
|
|
GEO
|
Географическое измерение. От G1 до G5 в нашей моделе. Собственно обособленные подразделения предприятия по территориальному признаку.
|
|
MONTH
|
Номер месяца года
|
|
YEAR
|
Номер года. В модель закачено 3 года: 2012, 2013, 2014.
|
|
ACT_RE
|
Фактическое (ACTuals) количество, выручка и т.д., либо уточненный план (RE) по количеству, выручке и т.д. на оставшуюся часть года.
|
|
BP
|
Плановое количество, выручка и т.д.
|
Извлечение данных
Я рассматривал 3 варианта:
Сводная таблица - с её помощью удобно извлекать данные в нужных разрезах, но она не может быть конечной таблицей, откуда, например, диаграмма будет забирать свои ряды данных. Нам могут потребоваться разные разрезы и тогда сводных таблиц надо иметь несколько, либо программно получать данные из сводной таблицы, последовательно меняя фильтры, забирать куда-то промежуточные данные, опять менять фильтры, опять забирать данные... Я предвижу тут значительные трудности и большой объём работы.
Формулы рабочего листа - это более гибкий и надёжный вариант, если только удасться подобрать такие формулы, чтобы можно было быстро извлекать нужные ряды в нужных разрезах. И такая функция в Excel есть. Это СУММЕСЛИМН (SUMIFS). Самый предпочтительный вариант, на мой взгляд.
Специализированные макросы - большой объём работы. В случае смены модели - переделка программы, а если делать в общем виде, то слишком сложно. Нет, чистый VBA тут не применим, если только, как комбинация со сводной таблицей.
СУММЕСЛИМН (SUMIFS)!
Вот наиболее полезная и универсальная выборка, которая потребуется нам на первых порах. Давайте её получим из листа DATA. Обратите внимание, что выборка имеет параметры, помеченные красными кружками с номерами от 1 до 4. Соответствующие ячейки содержат выпадающие списки, при помощи которых можно выбирать тип бизнеса (BUS), регион (GEO), год (YEAR), сумму (ACT_RE или BP).
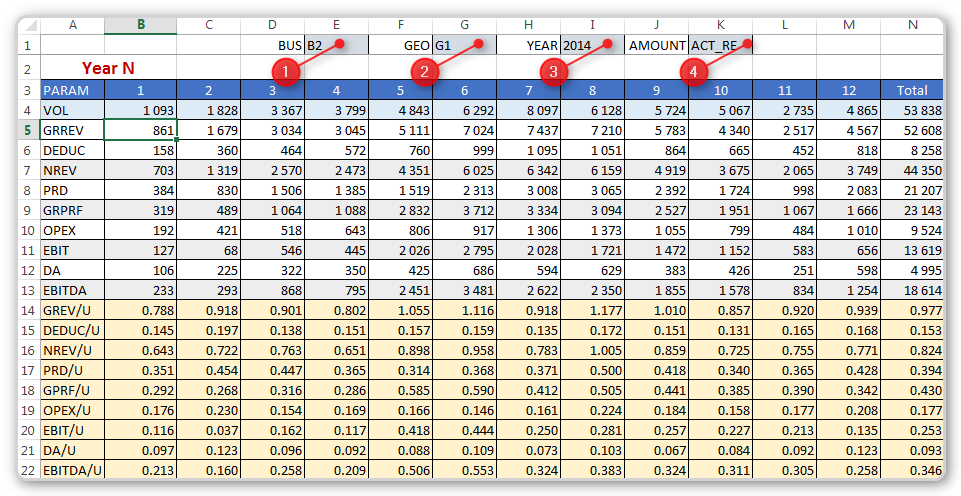
Давайте разберём формулу из ячейки B4, которая извлекает объём продаж за январь месяц с учётом указанных в фильтре значений типа бизнеса, региона, года и типа суммы.
=СУММЕСЛИМН(ДВССЫЛ(valAMOUNT);TYPE;$A4;BUS;valBUS;GEO;valGEO;YEAR;valYEAR;MONTH;B$3)
=SUMIFS(INDIRECT(valAMOUNT);TYPE;$A4;BUS;valBUS;GEO;valGEO;YEAR;valYEAR;MONTH;B$3), тут:
- valAMOUNT, valBUS, valGEO, valYEAR - это именованные диапазоны, указывающие на ячейки с фильтрами (E1, G1, I1 и K1)
- TYPE, BUS, GEO, YEAR, MONTH - именованные диапазоны, ссылающиеся на соответствующие колонки листа DATA
- Первый параметр функции СУММЕСЛИМН указывает диапазон суммирования. Поскольку нам надо суммировать разные столбцы (столбец ACT_RE, либо столбец BP) в зависимости от того, что выбрано в ячейке K1 (она же именованный диапазон valAMOUNT). Именно в связи с этим использована функция ДВССЫЛ, которая возвращает именованный массив, так как в дипазаоне valAMOUNT содержится одноименная с соответствующими именованными диапазонами текстовая константа. То есть ДВССЫЛ идёт в диапазон valAMOUNT (а это K1), берёт из K1 текст "ACT_RE" и поскольку в данном файле объявлен диапазон с таким же именем, то функция и возвращает нам уже не текст, а соответствующий диапазон.
- Далее параметры идут парами: диапазон условия и условие. У нас есть 5 таких пар. Например, диапазону условия TYPE, который ссылается на колонку TYPE на листе DATA, поставлена в соответствие ячейка $A4, где указан параметр "VOL".
Таким образом, СУММЕСЛИМН суммирует с учётом множественных условий. Кроме этого, если в качестве какого-то условия указана звёздочка (*), то данный фильтр фактически отключается - возвращает все значения, которые есть в данном диапазоне условия.
Все остальные формулы в строках GRREV, DEDUC, PRD, OPEX, DA - полностью идентичны рассмотренной и вводятся путём стандартного протягивания (копирования). Остальные формулы на листе SELECT элементарны.
Что у нас получилось? Что мы узнали?
- Мы смогли грамотно спланировать структуру таблицы на листе DATA
- Мы используем единственный источник внешних данных
- Мы нашли способ довольно легко и надёжно делать необходимые нам выборки для отчётов и диаграмм, о которых речь пойдёт в следующих частях
В следующих частях
Мы сделаем универсальный интерактивный отчёт P&L на одном листе, а не на 10. А в следующих выпусках будем много эксперементировать с диаграммами, иллюстрирующими данный отчёт. До встречи!
Читайте также:
|
